Resposta rápida
In-sample (IS) é a janela de otimização onde o algoritmo é calibrado; out-of-sample (OOS) é a janela de teste cego, mantida isolada da otimização para medir robustez em dados inéditos. O OOS perde validade a cada reuso, então use Walk-Forward Ancorada contra a não-estacionariedade e um Holdout Set como validação final antes do deploy.
O que a pesquisa mostra: Sullivan, Timmermann e White testaram 7.846 regras de trading em 100 anos do Dow Jones: ajustando o data snooping pelo bootstrap, a melhor regra deixou de ser lucrativa no período out-of-sample — evidência de eficiência crescente. — Sullivan, Timmermann & White (1999), Data-Snooping, Technical Trading Rule Performance, and the Bootstrap (Journal of Finance, 54(5):1647-1691)
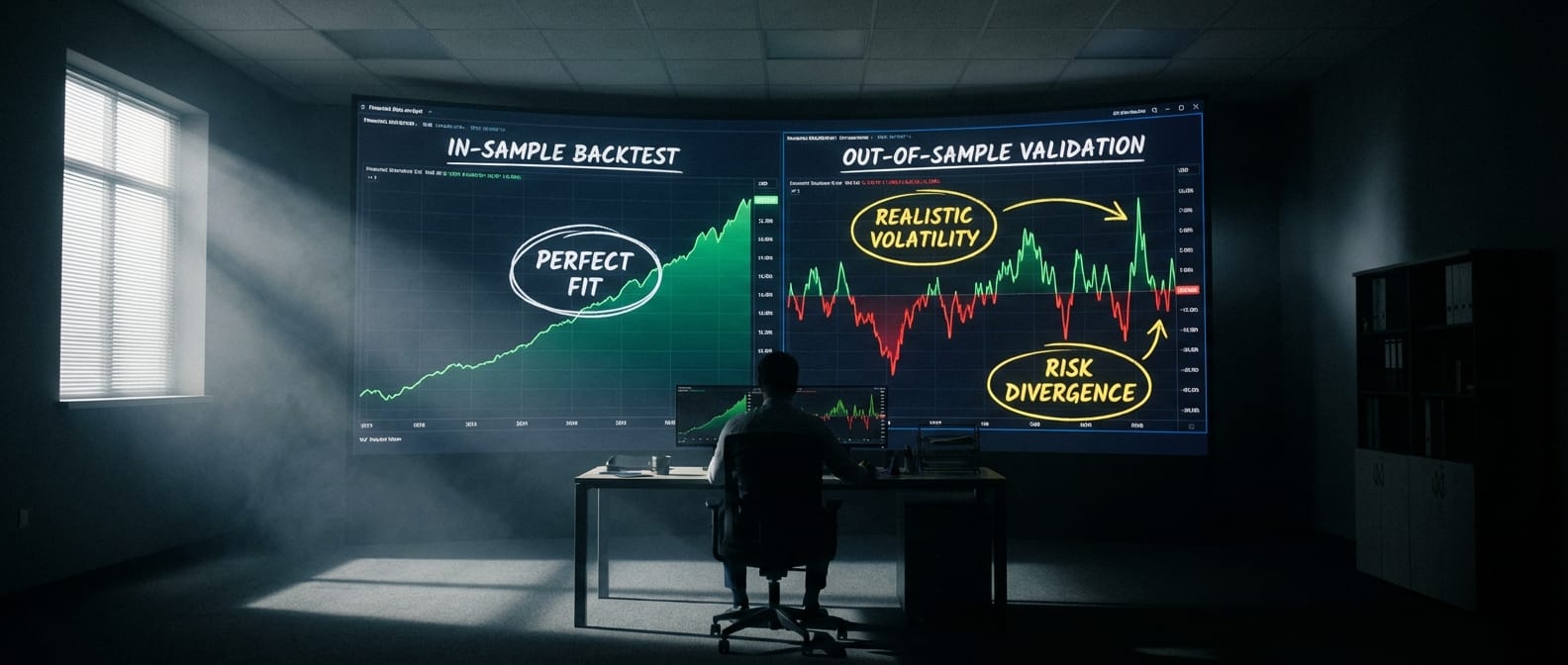
Todo trader quantitativo lembra perfeitamente de sua primeira grande desilusão. Você constrói um algoritmo, executa o Backtest nos dados do passado e a tela exibe uma curva de capital perfeitamente ascendente, com uma inclinação de 45 graus. O sistema parece infalível.
Então, você conecta esse código a uma conta real em sua corretora, e a estratégia desmorona e corrói seu capital logo no primeiro mês.
Por que isso acontece de forma tão sistemática com iniciantes? A resposta não está em um erro de digitação no código, mas na ausência de uma validação de dados históricos rigorosa.
O erro fundamental nasce quando aplicamos metodologias rasas e genéricas de Ciência de Dados diretamente em séries temporais financeiras.
Preços de ativos financeiros não são imagens estáticas usadas para treinar redes neurais genéricas. Eles são reflexos dinâmicos de um ecossistema complexo e mutável.
Quando um desenvolvedor ignora a natureza evolutiva do mercado, ele não está criando um modelo preditivo, está apenas desenhando o passado com alta precisão.
A falha de um modelo otimizado no laboratório ao operar em conta real é o sintoma clássico do Curve Fitting (sobreajuste). Seu modelo decorou o ruído histórico em vez de aprender a lógica estrutural dos preços.
Para corrigir essa falha, precisamos abandonar o empirismo superficial e adotar a validação quantitativa estruturada, onde a relação entre in-sample e out-of-sample dita a viabilidade do seu portfólio.
TLDR (Resumo Rápido)
- O mercado financeiro ensina que a divisão estática de dados falha em contas reais ao tratar preços como variáveis matemáticas estacionárias
- Esta falha metodológica gera sobreajuste e falsas expectativas de lucro
- Este guia substitui a regra estática de setenta/trinta por metodologias dinâmicas adequadas para o ambiente de trading quantitativo
- Você aprenderá a evitar o vazamento de dados e a blindar seus modelos contra as mudanças de regime financeiro
- O segredo fundamental reside em entender que a janela de teste cego perde sua validade e se queima irreversivelmente após o primeiro uso

Definição Formal e Estrutura Matemática da Validação de Séries Temporais
A base da engenharia de algoritmos de investimento exige uma separação rigorosa dos dados históricos disponíveis. O processo estatístico de validação começa dividindo o banco de dados em partições funcionais exclusivas.
A primeira delas é o In-Sample (IS), também conhecida como janela de otimização. Este é o ambiente de laboratório, o período de dados ao qual seu algoritmo é exposto para calibração, descoberta de regras e otimização de parâmetros.
A segunda partição é o Out-of-Sample (OOS), que atua como a janela de teste cego. Este segmento de dados deve permanecer estritamente separado e completamente invisível durante toda a fase de otimização. O objetivo do OOS não é melhorar o modelo, mas sim testar a robustez do algoritmo em dados inéditos.
Adicionalmente, arquiteturas profissionais exigem um Holdout Set, que é uma terceira reserva final de validação, mantida sob bloqueio absoluto e acessada apenas uma única vez antes de colocar capital em risco.
Um erro comum é tratar o trading quantitativo como um problema clássico de Machine Learning genérico, aplicando a tradicional proporção de setenta por cento para treino e trinta por cento para teste. Podemos definir essa divisão clássica matematicamente. Seja a série temporal total de preços P(t) em um intervalo de tempo T_{total}, a divisão estática define um ponto de corte arbitrário no calendário \tau:
T_{IS} = [0, \tau] \quad \text{e} \quad T_{OOS} = (\tau, T_{total}]Nesta fórmula, o conjunto de dados é quebrado em dois blocos rígidos, onde o período de treino T_{IS} vai do início até o ponto \tau, e o período de validação T_{OOS} assume o restante até o limite do conjunto de dados T_{total}. A simplicidade dessa equação é o que a torna ineficaz no mercado financeiro.
Estatisticamente, essa divisão fixa é inadequada porque o mercado é, por definição, não-estacionário. Isso significa que as propriedades estatísticas da série de preços, como média e variância, mudam ao longo do tempo.
Consequentemente, a função densidade de probabilidade dos retornos auferidos na janela de otimização não será igual à da janela de teste:
f_{IS}(R_t) \neq f_{OOS}(R_t)Esta equação ilustra o problema: a distribuição de retornos R_t no In-Sample f_{IS} é fundamentalmente diferente da distribuição de retornos no Out-of-Sample f_{OOS}.
Se você otimiza seu algoritmo para extrair lucro de um ambiente de juros baixos no In-Sample, a lógica desmorona quando o OOS apresenta um ambiente macroeconômico de juros altos e alta inflação.
A janela Out-of-Sample deve ser tratada como um ambiente hermeticamente fechado e isolado da otimização. Qualquer contaminação entre essas partições compromete o valor empírico do teste, transformando a validação em uma ilusão estatística.
Intuição Estatística e Interpretação de Dinâmica de Mercado
Para traduzir a abstração matemática em realidade operacional, o desenvolvedor precisa dominar o “Dilema do Viés” (uma adaptação do Bias-Variance Trade-off para o trading). A escolha do tamanho do seu In-Sample é uma decisão estatística profunda que dita o tipo de erro que seu algoritmo cometerá.
Se você utiliza um In-Sample muito longo, como dez anos de dados intradiários contínuos, seu modelo sofrerá de alto viés temporal. Ele será forçado a encontrar uma média que funcione tanto em 2014 quanto em 2024.
Ao tentar se ajustar a uma década inteira, o algoritmo captura dados obsoletos e ignora a dinâmica microestrutural recente que governa os preços atuais.
Por outro lado, se você utiliza um In-Sample muito curto, de apenas três meses, seu algoritmo desenvolverá alta variância. Ele se adaptará ao ruído recente e às anomalias passageiras.
O modelo parecerá promissor no curtíssimo prazo, mas será incapaz de sobreviver a mudanças de fluxo institucional, pois aprendeu os tiques aleatórios do mercado, e não sua estrutura fundamental.
A solução exige que o desenvolvedor passe a pensar em regimes de mercado em vez de calendários lineares. Uma janela de treino robusta deve incluir períodos de Bear Market (baixa), Bull Market (alta) e Sideways Market (lateralização com choques de volatilidade).
Se o seu In-Sample engloba apenas um mercado direcional de alta patrocinado por estímulos governamentais, seu algoritmo aprenderá que comprar qualquer queda é a regra principal.
Quando o ciclo reverter, o Out-of-Sample revelará que sua estratégia era apenas uma alavancagem mascarada se beneficiando de uma anomalia macroeconômica direcional.
Dados de mercado não são vetores estáticos; são séries temporais estocásticas que mudam de comportamento, volatilidade e direção conforme os ciclos macroeconômicos e a liquidez do sistema.
Delimitação Negativa: O Que a Divisão de Dados Não Representa no Trading
Para construir fundações sólidas, precisamos desconstruir mitos primários. O primeiro passo é entender o que a divisão in-sample e out-of-sample definitivamente não é.
A separação de dados não é uma garantia contra perdas futuras. Mesmo o modelo estatístico mais bem validado sofrerá Drawdowns (rebaixamentos de capital) em conta real, pois o mercado pode gerar eventos sem precedentes na história registrada.
Em segundo lugar, a validação não é apenas um recorte no calendário civil — otimizando de janeiro a dezembro e testando no ano seguinte. Isso ignora a sazonalidade, os ciclos de rolagem de contratos futuros e os choques de liquidez, falhando em simular o estresse operacional contínuo.
O mito mais prejudicial é a crença de que a divisão de dados é um processo iterativo para forçar resultados positivos. O desenvolvedor altera parâmetros repetidamente com base no Out-of-Sample até o backtest dar lucro.
Isso não é validação; é vazamento de informações do futuro para o passado (Data Snooping). O objetivo real do OOS é rejeitar hipóteses fracas rapidamente, antes de arriscar capital.
(A transição para os cenários operacionais, estruturas de alta frequência e a matemática da ancoragem estocástica será o próximo passo fundamental para evitar o viés de seleção).
Como vimos, a não-estacionariedade dos mercados limita a validade das abordagens estáticas de divisão de dados. A transição do ambiente acadêmico para o terminal de negociação exige que o desenvolvedor quantitativo adapte suas ferramentas estatísticas à realidade operacional. A forma como manipulamos o data split é estritamente ditada pela frequência de negociação do algoritmo em desenvolvimento.
A rigorosa divisão e isolamento de dados históricos serve como um mecanismo para rejeitar modelos superajustados, e não como uma ferramenta iterativa para aprovar estatisticamente estratégias sem vantagem real.
Cenários Operacionais: Estruturação de Dados para Day Trade e Swing Trade
A frequência com que seu algoritmo interage com o mercado define a velocidade com que a validade de seus dados históricos decai. Estratégias de alta frequência lidam com um ecossistema que se transforma rapidamente, enquanto modelos de baixa frequência capturam movimentos macroeconômicos mais longos.
Para algoritmos de Day Trade, utilizar uma janela In-Sample de cinco a dez anos é um erro metodológico. A dinâmica microestrutural do livro de ofertas de uma década atrás não tem relevância estatística para a negociação intraday de hoje.
Nesse cenário, o In-Sample ideal abrange meses recentes, enquanto o Out-of-Sample restringe-se a semanas, exigindo re-otimização constante.
Em contrapartida, modelos de Swing Trade ou Position operam baseados em ineficiências que levam semanas ou meses para se corrigir. Para esses sistemas, é estatisticamente necessário que o In-Sample englobe ciclos macroeconômicos inteiros, capturando períodos de aperto monetário e afrouxamento quantitativo.
Essa disparidade cria a necessidade de uma arquitetura de dados customizada. A tabela abaixo parametriza a relação ideal entre a modalidade operacional e a estrutura de divisão de dados.
| Modalidade | Tamanho ideal do In-Sample | Tamanho ideal do Out-of-Sample | Frequência de Re-otimização |
|---|---|---|---|
| Algoritmos de HFT/Scalping | 1 a 3 meses | 1 a 5 dias | Diária ou Semanal |
| Day Trade Clássico | 6 a 12 meses | 2 a 4 semanas | Mensal ou Trimestral |
| Swing Trade Quantitativo | 5 a 10 anos | 1 a 2 anos | Semestral ou Anual |
A microestrutura do mercado apresenta decaimento dinâmico; isso degrada a validade de dados de tick muito antigos de forma tão severa que utilizá-los para otimizar operações intraday modernas tende a gerar falsos positivos estatísticos.
Parâmetros Críticos de Modelagem e a Metodologia Anchored Walk-Forward
Para superar as limitações da divisão estática, a modelagem quantitativa frequentemente adota a Anchored Walk-Forward Analysis (AWFA). Esta é a base de um backtest robusto.
Em vez de um único corte no calendário, o AWFA simula a passagem do tempo de forma iterativa, replicando o que o algoritmo fará na conta real: aprender com o passado disponível e operar um futuro imediato e desconhecido.
Na metodologia ancorada, a janela de otimização (In-Sample) expande-se progressivamente, mantendo seu ponto de origem fixo no passado. Simultaneamente, a janela de teste cego (Out-of-Sample) desloca-se para a frente no eixo do tempo. Cada iteração produz um segmento de performance OOS inédito.
Podemos formalizar a iteração AWFA matematicamente. Para cada passo k, a janela In-Sample expansiva é definida por:
IS_k = [t_0, t_0 + w_{IS} + (k-1)w_{step}]Logo à frente dessa janela de treino, alocamos o segmento de validação. O Out-of-Sample rolante correspondente àquela iteração é formulado como:
OOS_k = (t_0 + w_{IS} + (k-1)w_{step}, \ t_0 + w_{IS} + k \cdot w_{step}]Após executar todas as iterações disponíveis, o desenvolvedor concatena os retornos de todas as janelas OOS_k. O resultado é uma curva de capital construída sobre dados que eram invisíveis ao otimizador em seus respectivos momentos. Se essa curva concatenada apresentar lucro consistente, o modelo demonstra maior robustez estrutural.
A calibração rigorosa desse processo depende da escolha exata de três variáveis fundamentais.
| Parâmetro | Definição Técnica | Impacto no Modelo |
|---|---|---|
| t_0 (Ponto de Ancoragem) | Marco zero absoluto da série temporal de dados históricos utilizada. | Define o início do aprendizado. Deve preferencialmente coincidir com uma mudança conhecida de regime macroeconômico. |
| w_{IS} (Janela Inicial) | Comprimento do bloco de dados In-Sample na primeira iteração (k=1). | Um w_{IS} muito curto impede a convergência estatística na primeira rolagem, gerando parâmetros ruidosos logo no início do teste. |
| w_{step} (Passo de Rolagem OOS) | O tamanho exato do salto temporal da janela de validação a cada nova iteração. | Dita a agilidade do modelo. Passos longos testam a estabilidade de longo prazo; passos curtos simulam re-otimizações frequentes. |
A Análise Walk-Forward Ancorada é uma ferramenta eficaz contra a não-estacionariedade, pois obriga o algoritmo a provar sua capacidade preditiva não em um único recorte temporal, mas através de múltiplos ciclos iterativos de evolução de preços.
Gestão de Risco Quantitativa e Dimensionamento Baseado em Validação
A validação de dados não serve apenas para aprovar ou reprovar um algoritmo; ela é uma métrica fundamental para o gerenciamento de capital. O desempenho observado na janela Out-of-Sample concatenada deve guiar o Position Sizing (tamanho da posição) na conta real.
É uma premissa empírica da modelagem que as métricas de retorno e risco sofrerão degradação (haircut) quando o sistema migrar do In-Sample para o Out-of-Sample. Essa variação é normal.
Se o seu algoritmo apresentou um Índice de Sharpe de 2.0 na janela de otimização, é provável que ele entregue um valor inferior na validação cega.
Um erro comum é dimensionar o risco da conta real baseado na performance e no Drawdown máximo obtidos exclusivamente no In-Sample. Como a janela de treino é um ambiente otimizado, o rebaixamento de capital ali tenderá a subestimar o estresse financeiro real.
O dimensionamento requer a aplicação de algoritmos de alocação utilizando as métricas degradadas obtidas no teste Out-of-Sample iterativo. Se o OOS apresentou uma queda de performance aceitável em relação ao IS, o capital alocado deve ser ajustado para suportar esse nível de ineficiência de forma segura.
Existe uma degradação natural da relação Risco/Retorno quando o algoritmo migra da fase de testes para a complexidade da conta real; o capital deve ser dimensionado para suportar o estresse operacional mapeado no Out-of-Sample.
Validação Cega e Armadilhas Estruturais (A Queima do OOS)
Todos os processos detalhados perdem o valor se o desenvolvedor cometer a contaminação de dados. As armadilhas estruturais mais comuns são o Look-Ahead Bias (Viés de Antecipação) e o Data Snooping (Bisbilhotar Dados).
O Look-Ahead Bias ocorre geralmente por erros lógicos no código, quando o algoritmo utiliza uma informação que ainda não existia no momento em que a decisão de trade foi tomada. Por exemplo, utilizar o preço de fechamento do dia para decidir uma entrada que ocorreu na abertura daquele mesmo dia. O modelo acessa o futuro para operar o presente.
A armadilha comportamental mais nociva é o Data Snooping, que dá origem à “Queima do Out-of-Sample” (OOS Burning). Se você testa o modelo no OOS, o resultado é negativo, e você altera parâmetros do código para testar novamente nos mesmos dados OOS, você destruiu a separação cega.
Neste exato momento, o Out-of-Sample é matematicamente transformado em um In-Sample estendido. A cada nova tentativa no mesmo conjunto de dados, a probabilidade de aprovar um modelo puramente por sorte (falso positivo) aumenta severamente:
P(\text{Falso Positivo}) = 1 - (1 - \alpha)^NOnde \alpha é o nível de significância e N é o número de tentativas ou ajustes feitos testando na mesma janela OOS. Se você iterar 14 vezes (N=14), a chance de achar um backtest lucrativo que seja puro ruído estatístico ultrapassa os 50%. O modelo torna-se estatisticamente inválido.
Se o teste Out-of-Sample iterativo falhar consistentemente, a hipótese principal deve ser descartada. O rigor quantitativo exige a formulação de uma nova ineficiência de mercado a partir do zero, em vez de forçar adaptações em um modelo reprovado.
(O descarte de modelos falhos é apenas a proteção inicial. A seguir, consolidaremos o protocolo sistemático de implementação e o checklist de aprovação final).
A regra fundamental é clara: O conjunto de dados Out-of-Sample atua como uma validação de queima única; ele perde sua confiabilidade preditiva a cada reuso sucessivo.
Desconstrução de Falácias Empíricas na Otimização de Algoritmos
A transição para a execução em tempo real exige a eliminação de vieses metodológicos. A otimização de parâmetros não deve ser tratada como um simples exercício de ajuste visual de curvas, sob o risco de alocação de capital em algoritmos com expectativa matemática negativa.
A relação entre o in-sample e o out-of-sample trading é a própria base da gestão de risco estatística. Para consolidar um modelo de validação, é imperativo evitar os erros mais comuns.
A tabela abaixo confronta os mitos estabelecidos com a realidade estrutural da modelagem quantitativa.
| Mito Estabelecido | Realidade Estrutural | Como Evitar na Prática |
|---|---|---|
| A regra estática do 70/30 funciona sempre | Assumir uma proporção IS/OOS engessada ignora a não-estacionariedade das séries financeiras. O mercado altera seus regimes de liquidez e volatilidade, tornando partições cronológicas rígidas menos relevantes. | Substitua recortes rígidos de calendário pela Análise Walk-Forward Ancorada (AWFA), validando o modelo iterativamente em múltiplos cenários. |
| O OOS pode ser reutilizado se eu alterar só um parâmetro | A reutilização transforma a janela cega em ambiente de treino (Data Snooping). A probabilidade de encontrar um falso positivo aumenta a cada nova tentativa (Deflação do Índice de Sharpe). | Trate a janela OOS como validação de uso único. Se o teste falhar estruturalmente, reconstrua a hipótese central. |
| Backtest linear indica um robô robusto | Curvas de capital perfeitamente ascendentes, com ausência de drawdowns, costumam ser a assinatura do Curve Fitting. O algoritmo decorou o passado, perdendo capacidade preditiva. | Limite os graus de liberdade do código e introduza custos friccionais realistas e slippage na modelagem In-Sample. |
A engenharia quantitativa visa encontrar assimetrias probabilísticas estruturais que sobrevivam à mudança de regimes, e não ajustar o passado para gerar métricas ideais no laboratório.
Protocolo Sistemático de Implementação e Checklist de Validação
A criação de um robô de investimento profissional exige um fluxo de trabalho estruturado. Qualquer desvio nas etapas de saneamento de dados, calibração ou teste cego pode resultar em um modelo fragilizado.
O processo de validação quantitativa submete os dados a filtros e testes sucessivos. A introdução do Holdout Set nesta rotina é o validador final.
Se o algoritmo sobrevive ao In-Sample expansivo e ao Out-of-Sample iterativo, ele deve enfrentar a prova definitiva: um bloco de dados oculto e intocado até o momento do teste pré-deploy.
Abaixo, detalhamos o checklist executivo recomendado para a validação de algoritmos financeiros.
-
✅ Fase 1: Seleção e Saneamento de Dados
- Ajuste os splits, agrupamentos e proventos (no caso de ações).
- Alinhe os vencimentos e realize o roll-over (para contratos futuros).
- Separe imediatamente uma porção dos dados e isole o Holdout Set.
- Pass: O banco de dados histórico espelha a realidade exata do feed da corretora.
- Fail: As séries temporais estão fragmentadas ou possuem lacunas.
-
✅ Fase 2: Treino In-Sample (IS)
- Defina uma hipótese lógica utilizando o menor número possível de parâmetros.
- Insira o slippage e as taxas de corretagem de forma realista no simulador.
- Otimize os parâmetros buscando sempre a estabilidade de drawdown, e não apenas o lucro máximo.
- Pass: O modelo apresenta retorno ajustado ao risco aceitável em variados regimes de mercado.
- Fail: A curva de capital sobe sem correções, indicando superajuste absoluto ao passado.
-
✅ Fase 3: Execução Out-of-Sample (OOS)
- Desloque a janela de teste utilizando o método iterativo AWFA.
- Meça com precisão a degradação de performance do robô.
- Respeite a proibição de retornar à Fase 2 baseando-se nos resultados vistos no OOS.
- Pass: A degradação do Índice de Sharpe no OOS é previsível e tolerável em relação ao In-Sample.
- Fail: A estratégia entra em colapso substancial e perde a viabilidade.
-
✅ Fase 4: Validação Holdout Final
- Execute o código estabilizado na reserva inviolável de dados (Holdout Set) uma única vez.
- Pass: O desempenho e as métricas de risco são similares aos do OOS iterativo. O modelo está pronto para deploy.
- Fail: Ocorre ruína ou degradação catastrófica. A hipótese inteira deve ser descartada.
A ausência de um protocolo rigoroso de validação em múltiplas camadas compromete a confiabilidade estatística do sistema automatizado.
FAQ Massivo: Validação de Algoritmos Financeiros
Qual a melhor proporção IS OOS para trading?
Não existe uma regra estática ideal, pois o padrão de setenta por cento de treino e trinta por cento de teste nem sempre atende à demanda das séries financeiras. A proporção ideal depende da captura de regimes de mercado completos. O In-Sample deve ser longo o suficiente para conter ciclos de alta, baixa e lateralização, e o OOS deve refletir as condições mais recentes.
Como evitar o curve fitting na criação de robôs de investimento?
Reduzindo os graus de liberdade do seu modelo algorítmico. Quanto menos parâmetros (como períodos de médias móveis ou alvos de stop) o sistema tentar otimizar simultaneamente, menor a chance de ele memorizar ruídos. Aliado a isso, deve-se aplicar um protocolo estrito de teste Out-of-Sample iterativo.
O que acontece se a estratégia falhar no teste Out-of-Sample?
A estratégia deve ser reavaliada estruturalmente ou descartada. Retornar ao código original para ajustar as regras e tentar forçar um resultado positivo na mesma janela cega destrói a validade estatística do teste.
Posso testar os mesmos dados OOS mais de uma vez?
Metodologicamente, não. A janela Out-of-Sample perde sua propriedade de “teste cego” após a primeira execução em que os resultados guiam alterações. Ao alterar o robô e testá-lo novamente nos mesmos dados, o risco de incorrer em Data Snooping aumenta drasticamente.
Qual a diferença estatística entre backtest e teste Out-of-Sample?
O backtest refere-se à simulação geral de uma estratégia em dados históricos. O teste Out-of-Sample é uma porção isolada desse conjunto, focada em validar a capacidade do modelo de extrapolar as regras aprendidas para dados que não influenciaram sua criação.
Quantos anos de dados históricos preciso para criar um robô quantitativo?
Depende da frequência operacional da sua estratégia. Algoritmos de Position e Swing Trade exigem janelas maiores (ex: 10 a 15 anos) para abranger grandes ciclos econômicos. Para sistemas de Day Trade e High-Frequency Trading (HFT), os micro-regimes mudam rapidamente, e meses de dados detalhados tick-by-tick costumam ser mais relevantes.
O que é a Análise Walk-Forward no mercado financeiro?
É uma metodologia iterativa de validação onde o modelo simula sua adaptação ao longo do tempo. A janela de otimização (IS) avança progressivamente, enquanto a janela de teste (OOS) rola constantemente para frente, avaliando a robustez em fatias consecutivas de dados inéditos.
Por que a divisão cronológica simples é considerada perigosa no trading?
Porque o mercado é regido pela não-estacionariedade. Dividir os dados cortando-os no meio pelo calendário civil pode agrupar ou isolar mudanças severas de política macroeconômica e choques de volatilidade repentinos em apenas um dos blocos.
O que é a deflação do Índice de Sharpe?
É a penalização estatística aplicada à relação de risco e retorno de uma estratégia em decorrência do número excessivo de iterações e testes realizados. Quanto mais vezes um desenvolvedor testa diferentes combinações de parâmetros no mesmo conjunto, maior a probabilidade de achar um resultado positivo ao acaso, superestimando o Índice de Sharpe real.
Qual o papel do conjunto Holdout (Holdout Set) na validação final?
O Holdout Set atua como o validador final do projeto. Diferente do OOS iterativo, o Holdout é mantido isolado até a conclusão do desenvolvimento. Ele é o teste definitivo do modelo, executado apenas antes da transição para o ambiente de conta real.
Indicadores defasados (lagging) prejudicam o In-Sample?
Se usados de forma exclusiva ou excessiva, sim. Indicadores derivados de preços passados possuem inércia algorítmica. O excesso de parâmetros baseados em atraso na otimização In-Sample pode dificultar a detecção de pontos de inflexão (turning points) no Out-of-Sample.
Custos friccionais (slippage) devem ser incluídos no In-Sample ou Out-of-Sample?
Devem ser incluídos em ambos de maneira consistente e realista. Omitir spread, corretagem e o impacto do slippage nas simulações gera métricas distorcidas e inviabiliza a projeção de performance real.
Conclusão e Diretrizes para o Desdobramento Operacional
O mercado financeiro demanda metodologias consistentes. A implementação profissional da relação in-sample e out-of-sample exige a compreensão de que iterar excessivamente sobre uma mesma série temporal consome a validade preditiva do seu modelo. Ajustar parâmetros repetidamente até o backtest se tornar lucrativo compromete a validação estatística.
O desenvolvimento quantitativo envolve aceitar que a degradação de performance entre a janela de otimização e a janela de validação é esperada. O papel da engenharia de algoritmos é mapear e parametrizar os limites operacionais com base nesse cenário validado.
Para estruturar um fluxo de desenvolvimento analítico, considere as seguintes diretrizes:
- Avalie criticamente backtests que não apresentam correções razoáveis, tratando curvas lineares perfeitas como potenciais indicativos de Curve Fitting.
- Segregue uma porção final do seu banco de dados mais recente (ex: 15 a 20%) e trate este volume como seu Holdout Set.
- Utilize preferencialmente a métrica de Anchored Walk-Forward Analysis (AWFA) para validação de séries temporais não-estacionárias.
- Interrompa ou reestruture a pesquisa de hipóteses cuja performance caia de forma insustentável ao realizar a transição da janela do In-Sample para os blocos do Out-of-Sample iterativo.
- Tenha ciência do impacto estatístico (Deflação do Sharpe) causado pelo número de vezes que o modelo é recompilado e testado nos mesmos dados para validação de hipóteses corretivas.
A consistência no ecossistema quantitativo exige disciplina técnica para validar e aceitar falhas metodológicas no laboratório, mitigando o risco de descobri-las sob a volatilidade de uma conta real.
Referências e Literatura Quant
- Sullivan, Timmermann & White (1999). Data-Snooping, Technical Trading Rule Performance, and the Bootstrap (Journal of Finance, 54(5):1647-1691). link.
- Sobre Overfitting em Backtests: Bailey, D. H., Borwein, J. M., Lopez de Prado, M., & Zhu, Q. (2014) – “Pseudo-Mathematics and Financial Charlatanism: The Effects of Backtest Overfitting“. Aborda como o sobreajuste em backtests leva a desempenhos enganosos e a falsas expectativas de lucro.
- Deflação do Índice de Sharpe: Lopez de Prado, M. (2018) – “The Deflationary Gap of the Sharpe Ratio“. Explora a degradação do Índice de Sharpe em cenários de múltiplos testes e a importância de ajustes para refletir a performance real.
- Não-Estacionariedade e Retornos de Ativos: Cont, R. (2001) – “Empirical properties of asset returns: stylized facts and statistical issues“. Detalha as propriedades empíricas dos retornos de ativos, incluindo a não-estacionariedade e suas implicações para modelos financeiros.
- Otimização e Tamanho da Janela In-Sample: Khandani, A. E., Lo, A. W. (2011) – “What is the optimal length of an in-sample window for technical trading strategies?“. Investiga a escolha do tamanho ideal da janela de otimização (In-Sample) para estratégias de trading técnico, considerando a estabilidade dos parâmetros.
- Validação e Data Snooping: White, H. (2000) – “A Reality Check for Data Snooping“. Apresenta uma metodologia para verificar a significância estatística de estratégias de trading, controlando o viés introduzido pelo “bisbilhotar dados” (data snooping).
Presente para Leitores: Robô de Gradiente Linear Gratuito
Estou liberando o acesso ao meu setup pessoal de Gradiente Linear sem custo nenhum. É só clicar e me pedir o arquivo.



