O mercado quantitativo passou por uma mudança drástica de paradigma na última década. Se você ainda baseia seus modelos preditivos exclusivamente no cruzamento de médias móveis, no Índice de Força Relativa (RSI) ou na leitura isolada de fluxo de ordens, você não está operando com vantagem.
Na verdade, você se tornou a liquidez para algoritmos institucionais mais sofisticados. A estrutura de dados tradicional, composta por preço, volume e o livro de ofertas (L2 Order Book), foi amplamente arbitrada pelos fundos de alta frequência (High-Frequency Trading).
Essa saturação significa que qualquer ineficiência visível nesses dados estruturados é precificada em frações de milissegundo. Para sobreviver e prosperar no cenário atual, a engenharia quantitativa exige a exploração de novas dimensões de informação.
O alfa contemporâneo reside cada vez mais na quantificação matemática de eventos do mundo real antes que eles cheguem ao pregão.
TLDR (Resumo Rápido)
- O mercado tradicional esgotou o potencial preditivo exclusivo de preço e volume.
- A nova fronteira quantitativa exige a captura e processamento de informações não estruturadas do mundo real.
- O uso de dados alternativos transforma ruído informacional em métricas precisas.
- A validação do sinal preditivo depende inteiramente de rigor matemático e testes estatísticos severos.
- Correlação estatística comprovada é o único escudo contra a ilusão de rentabilidade em backtests.

A Saturação do Mercado Tradicional e a Busca por Alpha Não Correlacionado
Para entender o porquê de os indicadores técnicos estarem obsoletos para a geração de Alpha consistente, precisamos olhar para a microestrutura do mercado. O mercado financeiro é, em sua essência, um mecanismo de desconto de informações.
Quando todos os participantes têm acesso instantâneo ao mesmo vetor de dados estruturados (OHLCV – Open, High, Low, Close, Volume), a capacidade preditiva dessa série temporal tende a zero. O mercado institucional construiu infraestruturas bilionárias apenas para arbitrar essas anomalias estruturais antes de qualquer investidor de varejo.
É neste cenário de escassez de oportunidades clássicas que surge a necessidade do uso de dados alternativos no algotrading. Em vez de olhar para o que o mercado já fez, a engenharia quantitativa moderna olha para dados periféricos que influenciarão o comportamento futuro das empresas e das economias.
Trata-se da coleta, higienização e modelagem de informações exógenas ao ambiente das bolsas de valores. O objetivo é encontrar vetores de dados que possuam correlação com os retornos futuros, mas que ainda não foram totalmente digeridos pela massa de participantes.
Essas fontes de dados não convencionais dividem-se em categorias muito específicas de exploração. A primeira é a análise de sentimento, que envolve capturar o fluxo de notícias globais ou postagens em redes sociais e convertê-las em um termômetro numérico de otimismo ou pessimismo.
A segunda engloba dados macroeconômicos consumidos em tempo real via APIs de bancos centrais, permitindo que algoritmos reajam a choques inflacionários segundos após a publicação oficial.
Além dessas, temos o web scraping de fundamentos e operações de varejo. Fundos quantitativos rastreiam preços de e-commerce diariamente para prever relatórios de inflação ou contabilizam vagas de estacionamento via imagens de satélite para estimar o faturamento trimestral de uma rede de varejo.
São dados brutos do mundo real, traduzidos para a linguagem matemática que um Execution Engine consegue compreender. O contraste entre as fontes de dados é significativo.
TABELA 1: Dados Tradicionais vs. Dados Alternativos
| Tipo de Dado | Fontes Principais | Formato | Frequência | Dificuldade de Processamento |
|---|---|---|---|---|
| Tradicional (OHLCV) | Bolsas (B3, NYSE), Corretoras | Estruturado (Séries Temporais, Tabelas) | Síncrona (Ticks, Minutos, Diário) | Baixa (Nativa para Pandas e bibliotecas comuns) |
| Tradicional (L2/L3) | Data feeds de alta performance (FIX) | Estruturado (Filas de ofertas dinâmicas) | Sub-milissegundo | Média (Exige infraestrutura de baixa latência) |
| Sentimento/Notícias | Twitter (X) API, Bloomberg, Reuters | Não Estruturado (Texto) | Assíncrona (Estocástica) | Alta (Exige modelos de Natural Language Processing – NLP) |
| Macroeconômico API | FRED, IBGE, Bancos Centrais | Semi-Estruturado (JSON, XML) | Mensal, Semanal (com divulgações pontuais) | Média (Desafio no alinhamento de timestamps) |
| Web Scraping / Varejo | E-commerce, Cartões de Crédito, Satélites | Não Estruturado (Imagens, HTML bruto) | Contínua ou em Lotes | Altíssima (Exige engenharia de dados pesada e limpeza de anomalias) |
A transição definitiva da modelagem quantitativa não ocorreu quando os computadores ficaram mais rápidos, mas sim quando os engenheiros perceberam que o verdadeiro alfa estava escondido na assimetria do caos de textos, imagens e dados não estruturados, longe da perfeição simétrica do livro de ofertas.
Fundamentação Matemática e Extração de Sinal Predito
A aquisição de dados não estruturados é apenas o primeiro desafio arquitetônico. Ter acesso a um milhão de tweets ou a milhares de relatórios econômicos mensais não gera lucro por si só.
O núcleo da operação quantitativa reside no que chamamos de Extração de Sinal. Este é o processo estritamente matemático de converter informações qualitativas, muitas vezes carregadas de ruído interpretativo, em um indicador preditivo contínuo e quantificável.
Em uma arquitetura robusta, não passamos textos ou imagens diretamente para o robô de execução. A engenharia de dados processa essa massa bruta e entrega ao modelo financeiro uma variável normalizada, comumente contida no intervalo matemático entre -1 (sinal de venda extremo) e +1 (sinal de compra extremo).
Contudo, normalizar um dado não prova a sua utilidade. Precisamos provar que esse sinal carrega poder preditivo sobre o eixo temporal do mercado. Para atestar essa validade, a métrica primária utilizada em pesquisa institucional é o Information Coefficient (IC).
O IC mede a capacidade real do seu modelo de prever o futuro, calculando a correlação estatística entre o sinal que você extraiu hoje e o retorno que o ativo apresentará amanhã.
IC = \rho(S_t, R_{t+1})Nesta formulação fundamental, \rho representa a função de correlação, frequentemente calculada via Pearson (para relações lineares diretas) ou Rank de Spearman (para monotonicidade). A variável S_t é o valor quantificado do seu sinal alternativo no momento presente t.
Já a variável R_{t+1} representa o retorno financeiro real do ativo no período subsequente. Se o seu IC flutua consistentemente ao redor de zero, sua arquitetura de dados não encontrou alfa; ela apenas empacotou o acaso matemático em uma nova variável.
A interpretação clínica dessa métrica nos leva a um conceito vital da engenharia: o Signal-to-Noise Ratio (SNR), ou relação sinal-ruído. Dados alternativos são, por natureza, repletos de lixo informacional. Um feed do Twitter durante o pregão possui um SNR baixíssimo.
A maior parte do volume de dados (o ruído) não tem impacto causal no preço do ativo. O desafio pragmático do desenvolvedor quantitativo é lidar com a esparsidade da informação útil, filtrando eventos estocásticos para extrair apenas os fragmentos que alteram o consenso de mercado.
A utilização de dados alternativos não é uma solução mágica preditiva que salvará estratégias com falhas de gestão de risco. Além disso, a proposta desta arquitetura não é ensinar o treinamento base de redes neurais ou as fundações semânticas do Natural Language Processing. Assumimos que o dado não estruturado já foi pontuado.
O nosso foco absoluto é a engenharia do fluxo de dados via API, a fusão assintótica dessas séries temporais complexas e a validação matemática inquestionável de que o sinal gerado não é um mero artefato do acaso.
Para avançar da teoria estatística para a implementação algorítmica, precisaremos de um pipeline capaz de conectar essas fontes caóticas ao rigor cronológico da bolsa. É exatamente na construção dessa infraestrutura de ingestão e na prova estatística do falso positivo que o verdadeiro diferencial técnico se estabelece.
Em finanças quantitativas, a intuição de que uma notícia move o mercado é irrelevante; se a correlação temporal cruzada entre o evento não estruturado e o retorno subsequente não puder ser provada matematicamente através do Information Coefficient, o modelo não possui um sinal, possui apenas uma hipótese falida.
Arquitetura de Ingestão e Fusão de Dados via API
Como vimos na seção anterior, a extração de alpha a partir de informações não estruturadas exige um distanciamento do formato clássico das bolsas. Para materializar esse conceito, precisamos de uma arquitetura robusta de ingestão. Em finanças quantitativas, dados não chegam limpos e organizados; eles precisam ser capturados, processados e injetados em um motor de decisão.
O pipeline quantitativo moderno opera através de um fluxo unidirecional e rigoroso: Data Source (API) -> Ingestion Layer -> Processing -> Feature Engineering (Sinal) -> Execution Engine.
O primeiro estágio, a Camada de Ingestão (Ingestion Layer), é responsável por estabelecer conexões seguras e resilientes com as fontes externas. No ambiente institucional, dependemos de APIs consolidadas que fornecem estabilidade de endpoint e documentação técnica precisa.
Fontes como a FRED API (Federal Reserve Economic Data) são mandatórias para séries históricas de inflação e juros. Para o fluxo de sentimento, a API do X (antigo Twitter) e terminais de notícias em tempo real são padrões da indústria. Já repositórios como Alpha Vantage e Quandl (Nasdaq Data Link) atuam como agregadores massivos de dados alternativos estruturados e semiestruturados.
Uma vez que o dado é ingerido e processado — convertendo arquivos JSON, XML ou textos brutos em variáveis quantitativas —, esbarramos no maior desafio arquitetônico do algotrading moderno: o alinhamento de séries temporais (Time-Series Alignment), também conhecido como Fusão de Dados.
O mercado financeiro tradicional opera em uma malha temporal síncrona. Os candles (OHLCV) são formados em intervalos determinísticos (minutos, horas, dias). Contudo, o mundo real opera de forma estocástica.
Um tweet de um executivo, um relatório de ganhos corporativos ou um choque geopolítico ocorrem em momentos aleatórios e assíncronos. Projetar esses eventos estocásticos sobre a malha síncrona do mercado sem vazar informações do futuro é um problema complexo de engenharia de dados.
Na prática de desenvolvimento em Python, isso exige operações de junção assintótica, conceitualmente conhecidas pelo uso de lógicas como o merge_asof da biblioteca Pandas.
Essa lógica não busca um casamento exato de horários, o que seria impossível. Em vez disso, ela atrela o evento alternativo (por exemplo, um dado de sentimento extraído às 14h32min15s) ao tick ou candle de mercado imediatamente subsequente ou antecedente, dependendo da regra de latência.
Um erro milimétrico neste alinhamento destrói a validade estatística do modelo, permitindo que o motor de backtest tome decisões baseadas em informações que, no tempo real da simulação, ainda não haviam chegado ao servidor.
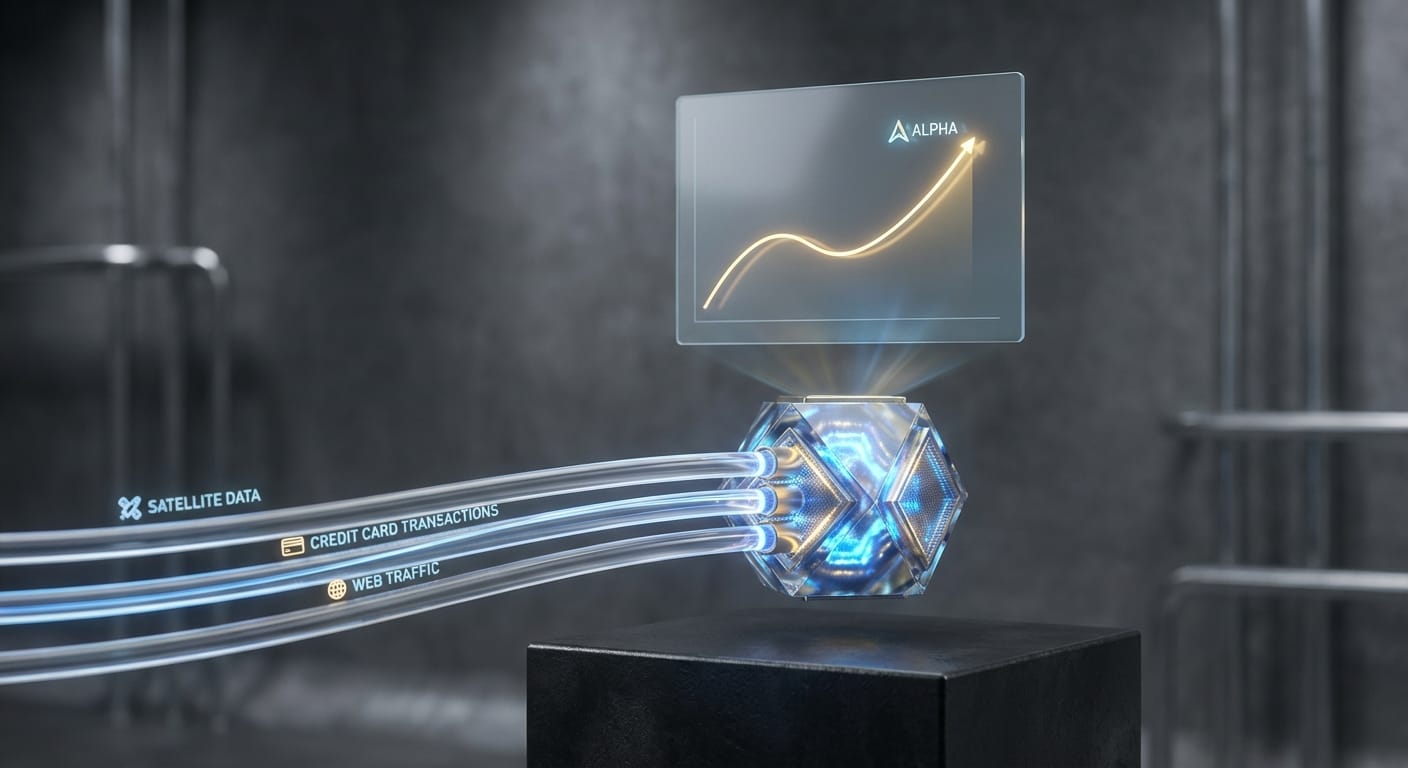
O Feature Engineering, penúltima etapa do pipeline, é onde ocorre a transformação desse dado fundido e temporalmente alinhado em um sinal preditivo contínuo. Independentemente da complexidade da fonte original — seja um relatório de cem páginas ou uma imagem de satélite —, o algoritmo de execução final deve receber um score matemático puro.
A arquitetura só é considerada completa quando o motor de execução (Execution Engine) recebe este vetor normalizado sem gargalos de memória e, mais importante, de forma totalmente dessincronizada das rotinas de coleta web.
O alinhamento temporal em finanças quantitativas não é um mero detalhe de formatação de banco de dados; projetar um evento assíncrono no timestamp errado é o caminho mais rápido para criar um robô de investimentos que é um gênio no backtest e um desastre absoluto no mercado real.
Aplicação Empírica: Cenários e Validação Estatística
Com a arquitetura de fusão de dados estabelecida, a aplicação empírica desses fluxos divide-se em cenários práticos baseados no horizonte de investimento. Estratégias quantitativas operam em diferentes espectros de frequência, e a escolha da fonte alternativa deve estar matematicamente alinhada com o tempo de retenção do ativo (holding period).
Podemos dividir essa exploração em duas frentes principais: a busca pelo Micro-Alpha e pelo Macro-Alpha.
O cenário de Micro-Alpha é dominado por operações intradiárias (Day Trade e High-Frequency Trading). Neste ambiente, a vantagem competitiva depende da velocidade de reação. A arquitetura exige conexões persistentes baseadas em WebSockets, mantendo canais abertos para receber fluxo contínuo de dados alternativos.
Técnicas agressivas de web scraping são empregadas para varrer fóruns financeiros e redes sociais em busca de anomalias de sentimento que precedem choques imediatos de volatilidade. A latência tolerável neste cenário é medida em milissegundos.
Em contrapartida, o Macro-Alpha foca em posições direcionais de médio prazo (Swing Trade ou Position). O pipeline dispensa conexões WebSocket de baixa latência e passa a utilizar chamadas REST padronizadas.
Aqui, a integração de APIs de dados macroeconômicos (como taxas de desemprego do IBGE ou decisões do FED) torna-se o núcleo do modelo. O algoritmo coleta relatórios densos, estrutura as expectativas contra os dados reais e monta posições diretas baseadas em desalinhamentos macroeconômicos invisíveis aos indicadores técnicos de curto prazo. As regressões são rodadas contra os retornos de fechamento diário (T+1).
TABELA 2: Comparativo de Cenários em Dados Alternativos
| Cenário de Execução | Horizonte de Operação | Tipo de API / Conexão | Objetivo Principal de Alpha | Latência Tolerável |
|---|---|---|---|---|
| Micro-Alpha | Intradiário (Minutos a Horas) | WebSockets (Fluxo Contínuo) | Captura de choques de volatilidade e assimetria de sentimento | Sub-milissegundo a poucos segundos |
| Macro-Alpha | Swing/Position (Dias a Semanas) | REST API (Chamadas sob demanda) | Antecipação de tendências estruturais e reajuste de prêmio de risco | Segundos a Minutos |
Independentemente do cenário escolhido, a integração de um novo sinal requer validação. Não basta observar o robô apresentar lucro; é necessário provar que o vetor alternativo causou o retorno.
A ferramenta institucional padrão para esta prova empírica é a Regressão Linear OLS (Ordinary Least Squares). Através dela, isolamos a capacidade explicativa do sinal em relação ao comportamento futuro do ativo.
A modelagem de validação assume que o retorno no período seguinte (R_{t+1}) é condicionado à direção e magnitude do nosso sinal quantificado no momento atual (S_t). Matematicamente, formulamos a equação fundamental da extração de alpha:
R_{t+1} = \alpha + \beta S_t + \epsilon_tNesta equação, \alpha representa o retorno base do ativo independente do nosso modelo, enquanto o \beta quantifica a sensibilidade do retorno em relação ao sinal alternativo. Se o sinal prevê uma alta e o mercado sobe, o \beta assume valor positivo e significativo.
O termo \epsilon_t representa o ruído branco inerente ao mercado — a fatia estocástica que nosso dado não estruturado não consegue explicar. A existência empírica de um \beta não encerra a investigação.
Em ambientes de altíssimo ruído, o acaso estatístico pode gerar falsas correlações. Precisamos rejeitar a hipótese nula de que o nosso sinal não possui efeito real (\beta = 0). Para isso, a engenharia financeira exige o cálculo da estatística-T (T-Statistic), que divide o coeficiente estimado pelo seu erro padrão:
t = \frac{\hat{\beta}}{SE(\hat{\beta})}TABELA 3: Parâmetros Críticos de Validação Estatística
| Métrica Estatística | Limite de Aceitação Institucional | Interpretação no Algotrading | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T-Statistic (t) | </td> <td style="border:1px solid #e0e0e0;padding:10px 16px;text-align:left;">t</td> <td style="border:1px solid #e0e0e0;padding:10px 16px;text-align:left;">> 2.0 | Confirma com aproximadamente 95% de confiança que o sinal alternativo não é fruto do acaso financeiro. | ||||||||||||||
| P-Value | < 0.05[/katex]</td>
<td style="border:1px solid #e0e0e0;padding:10px 16px;text-align:left;">Probabilidade de observar um sinal com essa força preditiva se, na realidade, ele fosse puro ruído. Deve ser marginal.</td>
</tr>
<tr style="background:#f8f9fa;">
<td style="border:1px solid #e0e0e0;padding:10px 16px;text-align:left;"><strong>Information Coefficient (IC)</strong></td>
<td style="border:1px solid #e0e0e0;padding:10px 16px;text-align:left;">[katex]> 0.05 ou < -0.05[/katex]</td>
<td style="border:1px solid #e0e0e0;padding:10px 16px;text-align:left;">Mede a estabilidade transversal do sinal preditivo. ICs consistentes acima de 0.05 já sustentam estratégias altamente rentáveis.</td>
</tr>
</tbody>
</table>
<p>Mesmo com um [katex]t > 2.0, a gestão de risco na aplicação de dados alternativos possui adversários invisíveis. O primeiro é o custo computacional (Slippage de processamento). Processar milhares de textos via algoritmos de linguagem natural exige ciclos pesados de CPU/GPU.
O atraso entre a coleta do dado bruto, sua quantificação normalizada e a emissão da ordem de mercado pode fazer com que o preço já tenha sido arbitrado por players mais rápidos, transformando um modelo estatisticamente viável em um robô deficitário. O segundo adversário crítico é o Alpha Decay (Decaimento do Alpha). Em finanças clássicas, padrões gráficos duram anos porque a massa os observa simultaneamente. No universo dos dados alternativos, uma correlação empírica inédita — como o rastreamento de jatos corporativos via web scraping para prever fusões empresariais — perde seu valor preditivo de forma exponencial assim que grandes Hedge Funds descobrem o mesmo vetor de dados e automatizam a operação em massa. Por isso, o desenvolvimento de estratégias não convencionais não termina com a validação OLS. O modelo exige manutenção, recalibragem constante e vigilância contra a saturação da fonte. Contudo, todos esses esforços analíticos serão completamente inúteis se a arquitetura basal estiver contaminada por falhas metodológicas de simulação temporal, o que nos leva às armadilhas mortais que assolam a pesquisa quantitativa.
Armadilhas Quantitativas: Mitos e Riscos EstruturaisA construção de uma arquitetura baseada em dados não convencionais não se encerra na captura do dado bruto; a maior parte dos projetos quantitativos fracassa na etapa de fusão das séries temporais. Desenvolvedores inexperientes frequentemente conectam APIs de análise de sentimento ou bases macroeconômicas aos seus robôs e observam backtests com curvas de capital lineares e perfeitamente ascendentes. Na engenharia financeira institucional, uma curva de performance perfeita no primeiro teste não é motivo de comemoração, mas o principal indicativo de falha estrutural. O erro quase sempre recai sobre dois erros críticos de validação: o viés de antecipação e o sobreajuste. O Look-ahead Bias (Viés de Antecipação) é, sem dúvida, o erro mais letal ao se trabalhar com dados alternativos. Esse fenômeno ocorre quando o seu modelo estatístico tem acesso, durante a simulação passada, a informações que ainda não estavam publicamente disponíveis naquele exato milissegundo histórico. Ao integrar APIs econômicas, como a do FED (Federal Reserve) ou do IBGE, o desenvolvedor costuma realizar as mesclas no Pandas utilizando a data de referência do indicador econômico, vez de utilizar o timestamp exato de publicação. Imagine que um dado de inflação referente a janeiro seja publicado apenas no dia 15 de fevereiro. Se o seu algoritmo fizer a junção assintótica (via merge) usando a data "janeiro", o seu backtest passará a comprar ou vender ativos no início de fevereiro possuindo uma informação que o mundo real só conheceria quinze dias depois. O backtester falha em replicar a realidade, gerando métricas de Information Coefficient extraordinárias e completamente irreais. O segundo risco categórico é o Overfitting (Sobreajuste). Com o advento das bibliotecas de Machine Learning e da facilidade em realizar regressões em massa, surge a tentação de minerar conjuntos de dados não estruturados até que uma correlação positiva seja encontrada. Se você testar cem fontes diferentes de dados alternativos – do número de menções a um ticker no Reddit até variações na cobertura de nuvens sobre plantações de soja –, a estatística nos diz que, por mero acaso, algumas dessas séries apresentarão correlação com os retornos do ativo. O modelo se torna excessivamente treinado para o ruído passado e perde completamente a capacidade de generalização para o futuro. A principal defesa contra o overfitting é a separação rígida dos dados e a validação Out-of-Sample (OOS), garantindo que o algoritmo prove o seu valor em um cenário de dados invisíveis durante a fase de otimização. TABELA 4: Tabela de Mitos e Erros
Checklist de Implementação de Dados AlternativosImplementar um pipeline quantitativo que consuma, trate e valide dados exógenos ao mercado exige método. O processo de engenharia difere radicalmente do trading discricionário: não escrevemos a lógica de compra e venda sem antes ter o endosso da regressão linear atestando a presença do alfa. A padronização desse ciclo de vida garante que você não dedique meses programando um sistema de roteamento de ordens para um sinal que, estatisticamente, é um mero lance de moedas. A estruturação correta exige que a arquitetura separe a fase de ingestão assíncrona da fase de execução determinística. O protocolo a seguir descreve o caminho pragmático que transforma uma string de dados (JSON, XML ou texto não estruturado) num gatilho financeiro confiável e validado pela escola matemática institucional.
A adoção destas etapas cria uma blindagem metodológica. Passar pela homologação sem cuidar da assincronia e falhar na comprovação de significância OLS fará com que seu algoritmo interaja com ilusões. A execução sistêmica funciona como uma auditoria constante na sua própria pesquisa.
FAQ Quantitativo: Dados Não Convencionais no AlgotradingO que são dados alternativos em finanças quantitativas?São conjuntos de informações não convencionais geradas fora do ambiente interno das bolsas de valores. Eles englobam rastreamento de satélites, faturas de cartão de crédito, raspagem de páginas web, indicadores macroeconômicos antecipados e sentimento em redes sociais, operando como proxies primários para estimar a saúde financeira ou movimentações de preço de um ativo antes que essa informação chegue aos dados padronizados do mercado. Qual a diferença entre dados estruturados e não estruturados no trading?Dados estruturados organizam-se em tabelas matriciais exatas com horários perfeitos, como o preço de abertura, máxima, mínima, fechamento e volume (OHLCV). Dados não estruturados apresentam formatos caóticos, frequências estocásticas e não contêm marcações óbvias de linhas e colunas, como fotografias, arquivos PDF, comentários em blogs ou fluxos de áudio que exigem modelagem prévia antes de qualquer processamento matemático. Como conectar APIs de dados macroeconômicos ao Python?O protocolo padrão utiliza bibliotecas de requisição HTTP, especificamente o módulo nativo ou Após a chamada bem-sucedida da URL contendo parâmetros de consulta e chaves de segurança, o servidor retorna um arquivo (geralmente JSON). O dicionário aninhado deve ser extraído iterativamente e imediatamente convertido em um DataFrame da biblioteca Pandas com formatação para séries temporais cronológicas. Como integrar análise de sentimento em um robô de investimentos?A integração exige um componente intermediário focado em Natural Language Processing (NLP) atuando como um microservice. O robô consome as manchetes via API, e o motor de NLP converte o conteúdo em vetores numéricos identificando polaridades. Em seguida, ele entrega ao robô final apenas um valor contínuo escalado entre pontos negativos e positivos. O sistema de execução, então, ajusta as probabilidades de entrada com base no peso e direção dessa variável final. Quais as melhores fontes de dados alternativos para algotrading?As plataformas variam conforme a modalidade desejada de alpha. Para dados econômicos profundos, o FRED (Federal Reserve Economic Data) e bancos centrais são o padrão-ouro gratuito. Para séries temporais consolidadas corporativas, Quandl (Nasdaq Data Link) ou Estimize fornecem projeções superiores. Já o mercado intradiário reativo consome o firehose oficial da API do X (antigo Twitter) ou provedores corporativos ultra-rápidos como Bloomberg B-PIPE e Reuters Refinitiv. Como validar estatisticamente um sinal de trading alternativo?A validação descarta indicadores isolados ou cruzamento de linhas. Extrai-se o valor absoluto do seu sinal alternativo no instante inicial temporal e calcula-se a relação de sensibilidade direta com a diferença percentual de preço no instante imediatamente seguinte. Isso é feito estruturando uma regressão linear minimizando os erros quadrados ordinários (OLS), na qual o retorno financeiro opera como variável dependente perante o sinal testado. O que é o Information Coefficient (IC) em finanças?É o medidor matemático primordial da capacidade de precisão de um algoritmo financeiro. Ele calcula a correlação entre a previsão entregue pelo indicador quantitativo analisado e o real resultado verificado no mercado no momento posterior. Em ambientes de pesquisa institucionais rigorosos, um valor perfeitamente medido que supere barreiras marginais de correlação já é estatisticamente viável para sustentar a criação de estratégias consistentes. Como evitar o overfitting ao testar dados não convencionais?Exige-se a divisão severa do histórico da série temporal em no mínimo dois blocos: o conjunto focado no descobrimento das variáveis e pesos (treinamento) e uma reserva cega focada na validação (Out-of-Sample). Um modelo sobreajustado destrói a própria métrica durante a exposição à base que estava escondida do otimizador primário. Sendo imediatamente reprovado antes do capital ser comprometido, ele protege o patrimônio líquido da ilusão preditiva retrospectiva. O que é Look-ahead bias na fusão de séries temporais?Acontece quando o histórico utilizado para a junção vetorial concede ao modelo estatístico o acesso desleal a uma informação real que ainda não fora publicada para a sociedade naquele minuto verificado na simulação. No mercado retrospectivo, isso gera simulações de rentabilidade irreais. Na prática, destrói o modelo assim que este acorda para o fluxo dinâmico do pregão ao vivo. Como fazer web scraping para fundos quantitativos sem quebrar regras de latência?Delegando as operações de captura intensiva a infraestruturas de computação em nuvem operando de forma desvinculada do motor encarregado da baixa latência de execução de boletas. As rotinas scrapers trabalham em background periodicamente gravando as variações detectadas num banco residente em memória extremamente veloz. Dessa forma, o robô apenas realiza leituras leves já pré-processadas quando os sinais técnicos do gráfico exigirem. O que é Alpha Decay em estratégias baseadas em notícias?Reflete a erosão progressiva e inevitável na capacidade de geração de lucro que uma modelagem preditiva baseada em nova categoria de dados exibe com a passagem do tempo. Trata-se do efeito direto das instituições concorrentes decifrarem a mesma anomalia não estruturada e lançarem robôs simultâneos de liquidação e arbitragem contra as ineficiências identificadas, sufocando as margens e acelerando a saturação estatística da estratégia na bolsa. Por que o T-Statistic é crucial para aceitar um sinal preditivo?Ele é o delimitador que expulsa o evento ocorrido por simples sorte. Através do T-Statistic, é possível calcular a chance matemática do seu resultado parecer lucrativo devido à extrema aleatoriedade contida na regressão imposta às bases sujas e aos ruídos exógenos. Limiares padronizados superiores a 2.0 atestam, estatisticamente, uma taxa altíssima de confiança científica comprovando que a variável testada detém real dominância comportamental direcional. Conclusão e Próximos PassosO processamento e a correlação de dados não estruturados deixaram de ser privilégio exclusivo de Hedge Funds hiper-financiados em Nova Iorque ou Londres. A democratização proporcionada pela economia das APIs e pelas robustas bibliotecas de código aberto converteu uma tarefa antes impossível numa disciplina factível para o engenheiro independente. O limite competitivo na era digital deixou de ser a capacidade bruta de aquisição da informação do mundo. O rigor matemático exigido para extrair a assimetria valiosa de eventos estocásticos e atestar sua independência funcional a respeito do ciclo direcional indexado tornou-se a nova barreira de entrada. A teoria desacompanhada da verificação empírica não se sustenta. O desenvolvimento quantitativo exige uma abordagem pautada pela excelência e eliminação rigorosa das armadilhas da série temporal não estruturada. Para alcançar os níveis padronizados em ambientes de tesourarias quantitativas, propomos o avanço na prática seguindo o encadeamento a seguir:
Referências e Literatura Quant
Presente para Leitores: Robô de Gradiente Linear GratuitoEstou liberando o acesso ao meu setup pessoal de Gradiente Linear sem custo nenhum. É só clicar e me pedir o arquivo.
Quero meu Robô Gratuito
🔒 Acesso Direto no WhatsApp

Flavio AraújoArtigos: 103 |